
Récemment, j’ai pris connaissance d’une étude1 datant de 2015 remettant en cause un certain nombre de connaissances que je pensais être suffisamment sûres et vérifiées pour être utilisées au quotidien. Cette étude portant sur la reproductibilité d’une centaine d’études scientifiques dans le domaine de la psychologie nous apprend que seulement 36 % des études testées avaient des résultats significatifs par rapport à 97 % des recherches initiales.
En statistiques, le résultat d’études qui portent sur des échantillons de population est dit statistiquement significatif lorsqu’il semble exprimer de façon fiable un fait auquel on s’intéresse, par exemple la différence entre 2 groupes ou une corrélation entre 2 données.
Techniquement, on évalue cette fiabilité selon une méthode qui suit le raisonnement suivant : on part de l’hypothèse qu’un résultat soit vrai, ce qu’on nomme l’hypothèse nulle. Et on s’accorde une probabilité, c’est-à-dire ici un risque acceptable, de rejeter cette hypothèse nulle alors qu’elle serait en fait vraie. Ce risque d’erreur (noté α) est souvent fixé à 5%, mais parfois à des valeurs bien plus faibles selon les domaines. Enfin, on calcule ce risque-là sur cette étude en particulier (dit valeur p ou p-value), et on dira que l’étude est statistiquement significative si p ≤ α.
Dans l’étude, la taille d’effet de la réplication était en moyenne deux fois moins grande que celle de la recherche originale, ainsi la moitié des recherches en psychologie cognitive et trois-quart de celles en psychologie sociale n’ont pas pu être reproduites. En statistique, une taille d’effet est une mesure de la force de l’effet observé d’une variable sur une autre et plus généralement d’une inférence. La taille d’un effet est donc une grandeur statistique descriptive calculée à partir de données observées empiriquement afin de fournir un indice quantitatif de la force de la relation entre les variables et non une statistique inférentielle qui permettrait de conclure ou non si ladite relation observée dans les données existe bien dans la réalité.
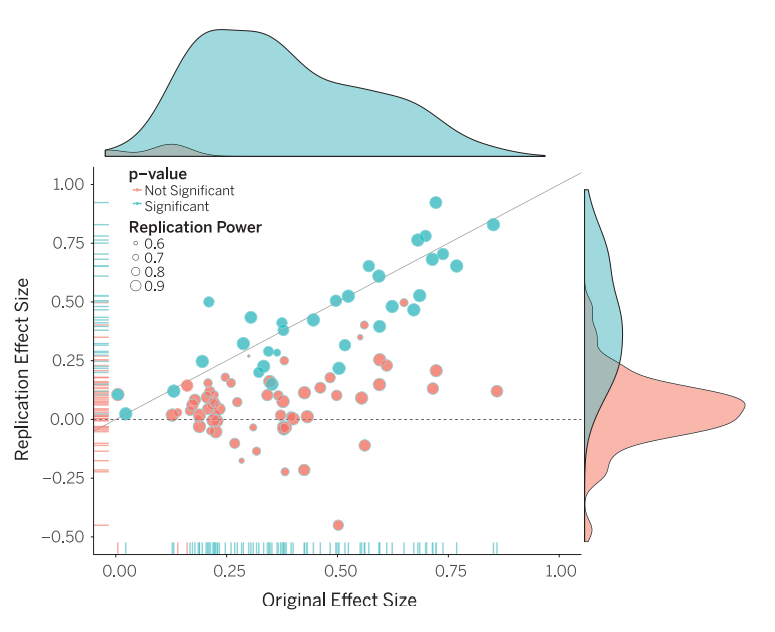
La ligne diagonale représente la taille d’effet de réplication égale à la taille d’effet originale. La ligne pointillée représente la réplication avec une taille d’effet de zéro. Les points sous la ligne pointillée sont des effets allant dans la direction opposée de l’effet originel. La densité des points est séparée en effets significatifs (bleus) et effets non-significatifs (rouges).
Cette étude2 de 2012 appuie l’importance du problème qui est que selon une analyse des recherches des 100 plus importants journaux de psychologie entre 1900 et 2012, seulement environ 1,07 % des publications sont des expériences de réplication et que seulement 78,9 % de ces expériences de réplication étaient concluantes.
Enfin, cette autre étude3 de 2015 tente de déceler pourquoi il est si difficile d’obtenir des études réplicables et donc méthodologiquement solides, qui permettraient de construire des connaissances plus fiables et utiles dans l’avancée de la science. Un des problèmes serait l’urgence dans laquelle sont publiées un certain nombre de recherches, n’attendant pas qu’une intuition soit confirmée ou infirmée, quand bien même elle pourrait l’être ou non. La fraude est aussi une possibilité, bien qu’elle puisse parfois ne pas être volontaire, les scientifiques étant soumis aux mêmes biais cognitifs que tout un chacun. Il est aussi souligné que les fonds alloués aux recherches ont leur importance sur la manière de travailler, les échéances de publications, etc.
Comme le montre cette dernière étude, le problème n’est pas inhérent au domaine de la psychologie, mais concerne bel et bien un grand nombre de disciplines assez différentes. Biologie (voir cet article), pharmacologie, sociologie, psychologie, géologie, chimie… Il semblerait que le problème soit connu depuis le début des années 2000, mis en avant par l’article de John Ioannidis, Why Most Published Research Findings Are False4 de 2005.
Mais pourquoi la reproductibilité5 est-elle si importante en science ? La reproductibilité réfère à l’habileté d’un chercheur à dupliquer des résultats d’une étude existante en utilisant la même méthode employée dans celle-ci. Ainsi, un second chercheur peut utiliser les mêmes données brutes pour construire une analyse et y implémenter une analyses statistique dans l’idée d’obtenir les mêmes résultats. La reproductibilité est donc une condition minimum nécessaire pour qu’une découverte soit crédible et informative.
J’ai donc fais quelques recherches supplémentaires, afin d’y voir plus clair. C’est ainsi que je suis tombé sur une vidéo de Lê Nguyên Hoang sur sa chaîne Science4All.
La vidéo de Derek Muller de la chaîne Veritassium est un peu moins technique et explique aussi bien le problème, avec cependant une conclusion quelque peu optimiste sur le futur de la publication scientifique. Je ne peux qu’aller dans son sens lorsqu’il précise que la méthode scientifique reste le meilleur moyen de réellement savoir ce que l’on sait, malgré toutes ses faiblesses.
L’optimisme ne s’arrête pas là puisque j’ai pu lire plusieurs articles qui expliquent que certains domaines scientifiques comme la psychologie cognitive6 (qui a connu des efforts de la part des chercheurs pour s’éloigner des mauvais résultats de 2015), la psychologie de la personnalité7 ou encore la philosophie expérimentale8 ont plus de succès en terme de reproductibilité et donc d’apports de connaissances solides. Tout n’est pas parfait, mais tout n’est donc pas perdu et c’est le principal.
Je me suis principalement appuyé sur les travaux de John Ioannidis dans ma réflexion et l’écriture de cet article. Il a mené un nombre important d’études sur la question de la fiabilité des résultats publiés dans les revues scientifiques, notamment sur pourquoi la science n’est pas nécessairement auto-correctrice9, sur la reproductibilité en sciences10, sur l‘importance de la taille de l’échantillon étudié11, sur comment améliorer la qualité des publications scientifiques12, sur l’efficacité de la recherche clinique13, sur l’importance du travail liant la recherche scientifique avec les politiques publiques14, et bien d’autres encore, une simple recherche sur Google Scholar permettra de sélectionner plus précisément ce qui vous intéresse.
Pour conclure, du moins provisoirement, il est important de garder à l’esprit que rien n’est jamais sûr à 100% ou 0%, bien qu’on puisse s’approcher toujours plus près de ces valeurs absolues. Personne n’a jamais vu de licorne ni fourni de preuves matérielles afin d’appuyer l’affirmation qu’elles existent. Pour autant, l’absence de preuve n’est pas la preuve de l’absence, et mon estimation ne peut donc pas rationnellement aller jusqu’au 0% absolu. Je suis tout au plus à 0.1%, jusqu’à obtenir, peut-être un jour, une preuve m’obligeant à réévaluer mon estimation. La pensée bayésienne me semble être aujourd’hui, avec les connaissances dont je dispose et de la crédibilité que je leur accorde, le meilleur moyen de jauger ce qui est crédible et ce qui ne l’est pas, ce qui est vraisemblable ou non, plausible ou pas. Je ferai sûrement un petit article dessus, puisque je n’ai pas grand chose à ajouter aux personnes dont j’ai partagé les vidéos.
L’objectif de cette catégorie, l’esprit éthique, est bien la transparence et le rassemblement de tout un tas de ressources permettant d’affuter son esprit critique, et je suis convaincu qu’un article sur la pensée bayésienne, à côté de ceux sur les sophismes, les études scientifiques, et celui sur les biais cognitifs, a toute sa place ici.
